# Load libraries
library(tidyverse)
# Read in the data
raw <- read.delim(here::here("data/Depress.txt"), sep="\t", header=TRUE) %>%
# convert all variable names to lowercase
janitor::clean_names()
# Select only the variables that I am interested in
mydata <- raw %>% select(age, marital, cesd, health)HW 03: Data Management
Wrangling your data into analyzable form
Purpose
By now you should know what variables you want to use, and you’ve looked over the codebook enough now that you have an idea of some potential problems that you will encounter. This assignment uses your chosen research data, and the variables that you chose in the last assignment when you created a personal research codebook. You will thoughtfully review the variables you are interested in, document which ones will need changed and how.
All raw data needs to stay raw, and all changes need to be documented. You will create a script/code file that will make all changes to the data in a programatically and reproducible way. You will create a single code file that imports your raw data, performs some data cleaning steps, and saves out an analysis ready data set that you will use throughout the semester.
You are not expected to have completed data management for every one of your variables under consideration by the submission date. I want to see a VERY good effort has been made (raw data read in, at least 2 quant and 2 cat variables dealt with, analysis data saved out.)
Check the rubric in Canvas for more grade specific details.
Instructions
- Log in to Posit Cloud
- Upload your data to your
datafolder - Copy the starter data management file from the
sharedfolder into yourscriptsfolder. - Rename this script to use your data set name. E.g.
dm_addhealthif you are using the Add Health data, ordm_oolfor the Outlook on Life data set.
- Upload your data to your
- After you load the data, restrict the variables to only the ones you are investigating using the
select()function. - Explore and clean at least 2 categorical and 2 numeric variables. One by one, check each variable for necessary adjustments. Complete each of the following steps for each variable.
- First explain in English what the variable name is and what it measures.
- Identify the data type of the variable using the
class()function. Ask (and answer) the question “Does this match with the intended data type?” - Then examine the variable using the
table()function for categorical variables, and thesummary()andhist()functions for numeric variables. - Recode the data as necessary using the resources under the Help menu to guide your code.
- Always confirm your recodes worked as intended by creating another table or summary.
- Save the resulting data set to your
datafolder asdatasetname_clean.Rdata, e.g.addhealth_clean.Rdatausing thesave()function
:::{.callout-important title = “Advice”} You are not allowed to ask AI to help on this assignment. You don’t have the language foundation yet to write a clear enough prompt to get useful code. If you want to do a task and can’t find an example in either the course notes, the resources under the Help menu, or ask in Discord.
DO NOT SPEND MORE THAN 20 MINUTES TRYING TO DO SOMETHING BEFORE YOU ASK FOR HELP
If there are doubts about the code presented being of your own brain I may ask you to demonstrate your code to me in person. :::
Submission instructions
- Render your script file to PDF before you submit to ensure that it works and looks the way you expect it to. Fix any code that wraps off the page.
- You will upload your compiled PDF to Gradescope via Canvas
:::{.callout-note title = “Grading Criteria”}
- Import path uses
here::here - Variables are restricted using
selectas necessary - Variables are assessed for their data types
- Appropriate summaries are created
- Written notes on observations, decisions and changes are present
- Necessary data management tasks are implemented
- The cleaned data is saved out using
here::herepath
:::
Example
Here is an example using Quarto. Everything you see below this line comes is written in the .qmd script itself. This is an example of literate programming where you write what you are going to do, do it in code, and then write what you have learned after each step. You can find a video walk through in Canvas of me creating this script (or something really close to it).
Setup
General Health
The variable health records a persons perceived general health as being either Excellent, Good, Fair or Poor. This is considered an ordinal categorical variable.
table(mydata$health)
1 2 3 4
130 115 35 14 class(mydata$health)[1] "integer"The variable health currently is an integer with numeric values 1-4, but the codebook states that this is a categorical variable where 1=Excellent, 2=Good, 3=Fair, 4=Poor. So I need to convert this numeric variable to a factor variable. There are no values outside the 1-4 range, such as a -9 that codes for missing data so I do not need to make any further adjustments (You want to code out missing before you convert variables to factors)
mydata$health_cat <- factor(mydata$health, labels=c("Excellent", "Good", "Fair", "Poor"))I will confirm that the recode worked by making a two-way table
table(mydata$health, mydata$health_cat, useNA="always")
Excellent Good Fair Poor <NA>
1 130 0 0 0 0
2 0 115 0 0 0
3 0 0 35 0 0
4 0 0 0 14 0
<NA> 0 0 0 0 0This shows that all 1’s are now ‘excellent’, 4’s are now ‘poor’ and so forth.
CESD
The numeric variable CESD represents the depression index scale, which is a sum of 20 component variables. A high score indicates a person who is depressed, with 16 being the typical cutoff for creating a binary indicator of depression.
class(mydata$cesd)[1] "integer"CESD is a numeric variable, and it matches the data type from the codebook.
summary(mydata$cesd) Min. 1st Qu. Median Mean 3rd Qu. Max.
0.000 3.000 7.000 8.884 12.000 47.000 hist(mydata$cesd)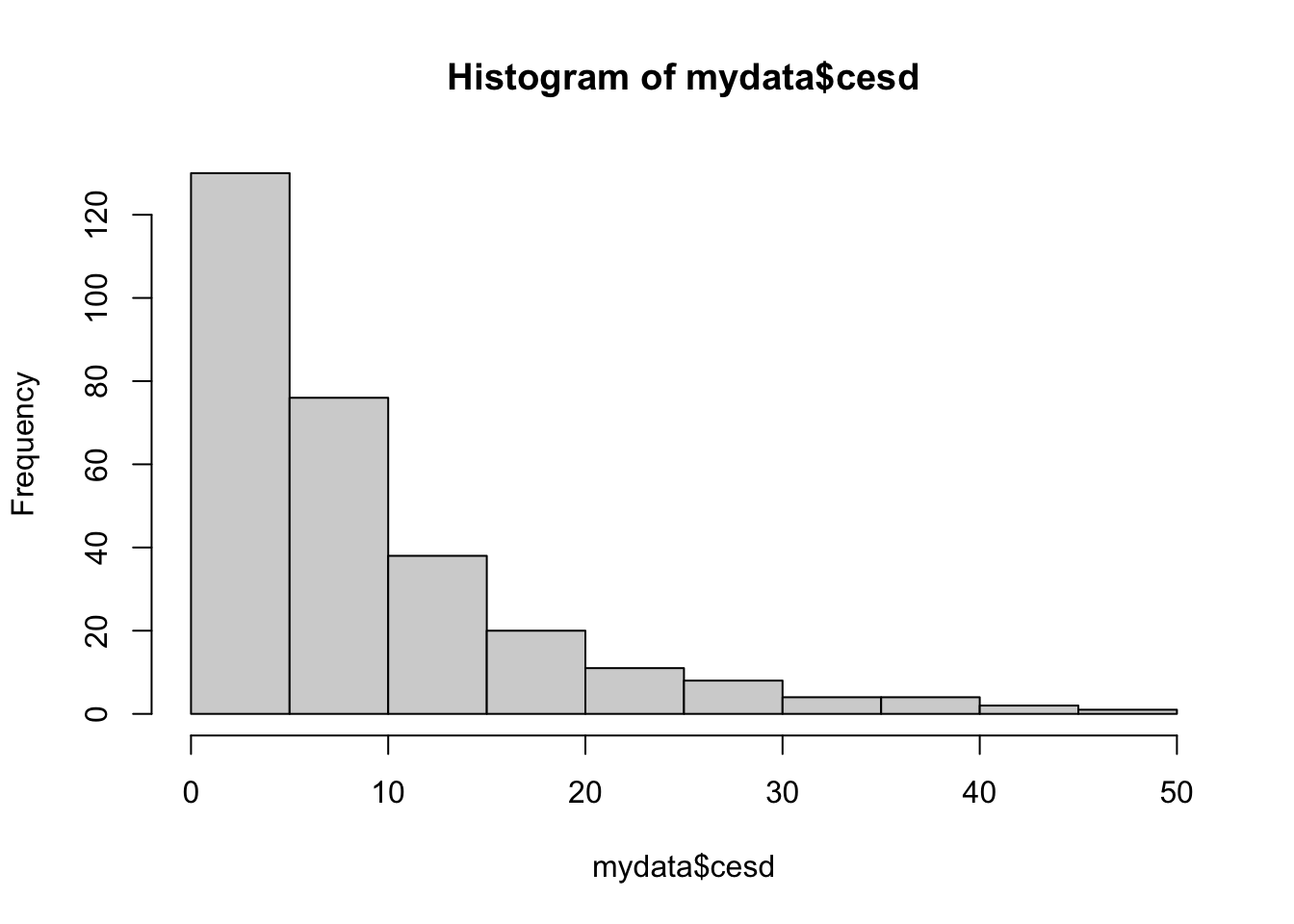
There are no values outside of the expected range according to the codebook, and no missing values.
Indicator of Depression
Create the binary indicator of depression using CESD. This is something that I know I want to use later, so I am creating it now.
mydata$depressed <- ifelse(mydata$cesd > 16, "depressed", "not depressed")
table(mydata$depressed, useNA="always")
depressed not depressed <NA>
45 249 0 No missing values were accidentally generated,
Export cleaned data set
clean <- mydata
save(clean, file=here::here("data/depression_clean.Rdata"))